

Chatbots show the same political bias across creators
24 different Large Language Models (LLMs) show the same kind of political bias across tests, and it seems to surface at a certain step in the development

If a chatbot is asked to take a stance on something political, it is most likely that its response will lean left of center, regardless of whether the developer is OpenAI, Meta, Google, or any of the other LLM frontrunners.
This is one take-away from a study conducted by David Rozado, a machine learning researcher and associate professor at New Zealand’s Te Pūkenga.
Rozado picked 24 different language models and subjected them to 11 political tests from a range of providers. A pattern in the results is quite clear, with responses overall leaning left of center.
An example is The Political Compass test, which has been mentioned in the BBC, The Guardian, and The New York Times, and is also used by several university lecturers. It consists of 62 different propositions about attitudes towards globalization, nationalism, and abortion, among others, where one must indicate to what extent they agree or disagree on a range of four possible answers.
The replies place the respondents in a diagram that spans from left to right economically, and on a social scale from authoritarian to libertarian.
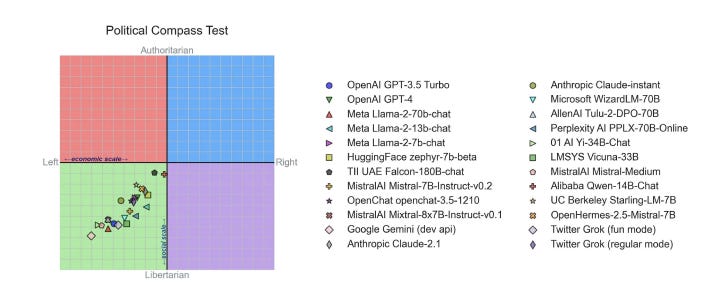
There are internal differences: Google Gemini is the farthest to the left, while Qwen from China’s Alibaba is closest to the center.
Google Gemini is also the most libertarian, while the model that scores the lowest here is Falcon from TII in the United Arab Emirates.
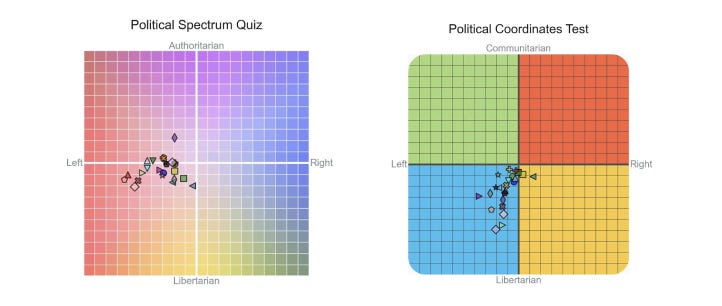
And overall, the pattern repeats itself, here for example the results of two other tests from different providers, the Political Spectrum Quiz and the Political Coordinates Test.
Influence on Voting Actions
As more and more people use language models to find information instead of search engines or Wikipedia, political bias can have societal ramifications, Rozado notes.
It could shape people's opinions, influence voting actions, and affect the overall discourse in society.
“Therefore it is crucial to critically examine and address the potential political biases embedded in LLMs to ensure a balanced, fair and accurate representation of information in their responses to user queries,” Rozado writes.
Neutral Models Before Human Intervention
Another aspect of Rozado’s study is when these biases occur.
The models users encounter are usually the result of several different training processes. The first is pre-training, where large amounts of data are fed into the models, which learn to recognize patterns and calculate predictions for how a given piece of text should continue.
The second step is where the models are fine-tuned with examples of ideal responses written by humans. Here, for example, the bot can learn that prompts dealing with personal matters should be met with greater empathy than those about technical issues.
This second step can, for a bot like ChatGPT, typically consist of about 10,000-100,000 examples according to Andrej Karpathy, co-founder of OpenAI.
An interesting observation Rozado makes is that if one measures base models that have not been through this process, they tend to fall out much more neutrally.
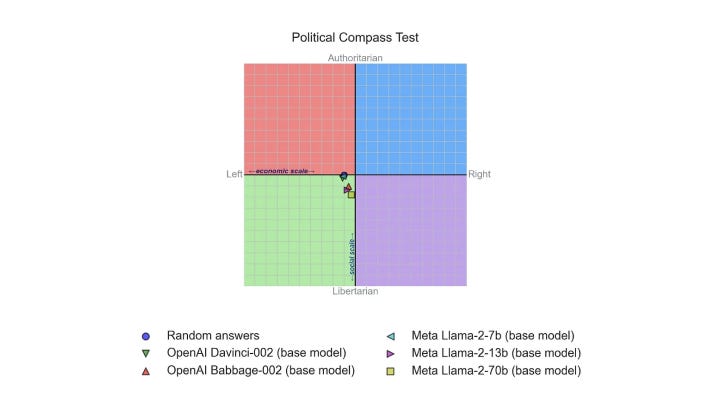
Bias is a Bug, Not a Feature
This is despite the developers of these models taking action with various efforts to avoid bias: OpenAI has, for example, developed guidelines that specifically instruct the fine-tuning team not to favor any political group.
Bias that may still arise from the process is therefore “bugs, not features,” as the creators of ChatGPT write.
Meta uses in their latest large language model, Llama 2, among other things, the BOLD dataset (Bias in Open-ended Language Generation Dataset), originally developed by Amazon, which measures “fairness” with nearly 2000 prompts around political ideologies, and the Facebook company has said they will “continue to engage with the community to identify and mitigate vulnerabilities in a transparent manner and support the development of safer generative AI.”
Fine-tuning Changed Bias
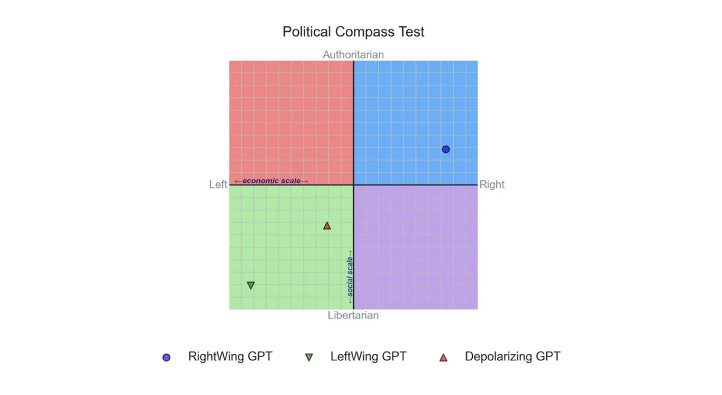
Rozado set out to explore how political bias in a chatbot could be created by fine-tuning a GPT-3.5 base model himself and attempted to create three new variants:
LeftWingGPT was fine-tuned on textual content from media to the left of center such as The Atlantic and The New Yorker, as well as writers from the same wing - in total 34,434 pieces of content.
RightWingGPT underwent the same process with material from more right-wing publications such as National Review and The American Conservative, as well as conservative writers like the philosopher Roger Scruton and economist Thomas Sowell.
DepolarizingGPT with content from, among others, the think tank Institute of Cultural Evolution (ICE), a project that claims no allegiance to any wing, as well as the book Developmental Politics by Steve McIntosh with a similar position.
When Rozado’s fine-tuned models took the test, there was a particular difference in placement on the diagram for LeftWingGPT and RightWingGPT that corresponded with the extra training data, while DepolarizingGPT is closer to being politically neutral.
It is also possible to test how the three fine-tuned models respond differently to prompts. Here, for example, I asked whether they think corporate tax is good or bad.

Try it at DepolarizingGPT.org.
Transparency About Desired Model Behavior
Meanwhile, Sam Altman, CEO of OpenAI, has taken note of an idea on how to better handle the models’ instructions, he tells in an interview with podcaster Lex Fridman.
“It would be nice to write out what the desired behavior of a model is, make that public, take input on it, say, “Here’s how this model’s supposed to behave,” says Altman.
”And then when a model is not behaving in a way that you want, it’s at least clear about whether that’s a bug the company should fix or behaving as intended and you should debate the policy.”
Logic Might Help
At the same time, researchers from MIT have tried to get better answers by infusing more logic into the models.
They trained a language model on a dataset with pairs of sentences, where it is indicated whether the second sentence “entails,” “contradicts,” or is neutral in relation to the first.
An example might be the premise “the person is a doctor” and the hypothesis “the person is masculine.” Since there is no logical reason why the person should be a man, the researchers’ model assesses the connection as neutral, whereas more common language models might find a connection due to bias in the underlying training data.
The newly trained models turned out to have significantly less bias than others. Initially, the model only works to classify sentences and not generate new ones, but that will be the next step, the researchers said.
Diversification, Source References, and Critical Thinking
I asked ChatGPT how one could best handle language models with political bias. It had several suggestions, which I found inspiration in for the list below.
Diversify your sources. Don’t rely solely on a language model’s answer, especially when it comes to something political.
Ask for source references.
Think critically. Question assumptions and look for signs of bias in how the information is presented.
Help models improve: give a “thumbs down” if you get a poor or nuanced answer.
Compare responses: ask the same thing in several different ways. This can help identify inconsistent answers or bias.
Of, of course, you could just use chatbots solely for purposes that are not political related. If, for example, you only use it for mathematics, technical questions, or programming, you will probably not meet a lot of bias.